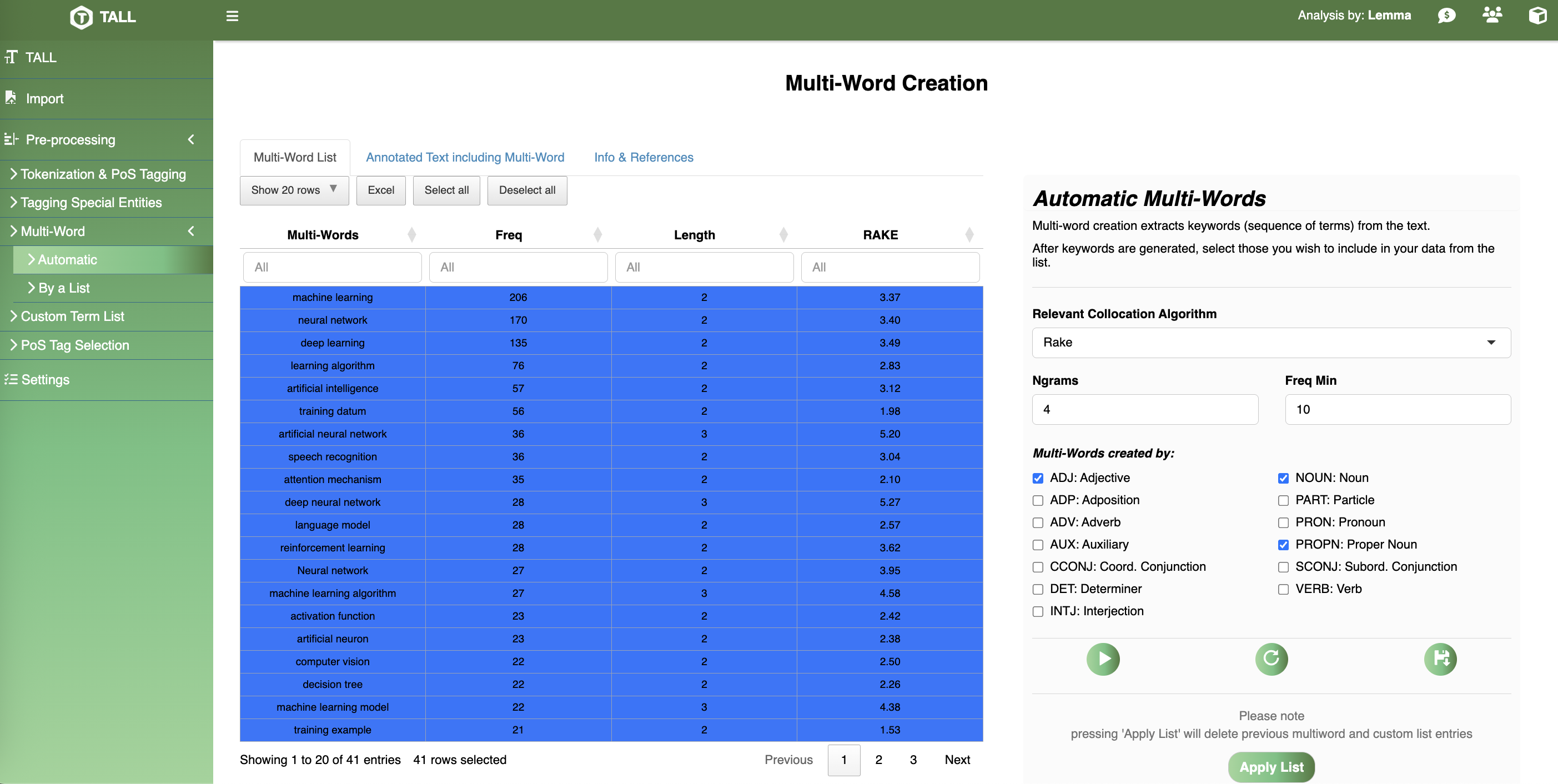
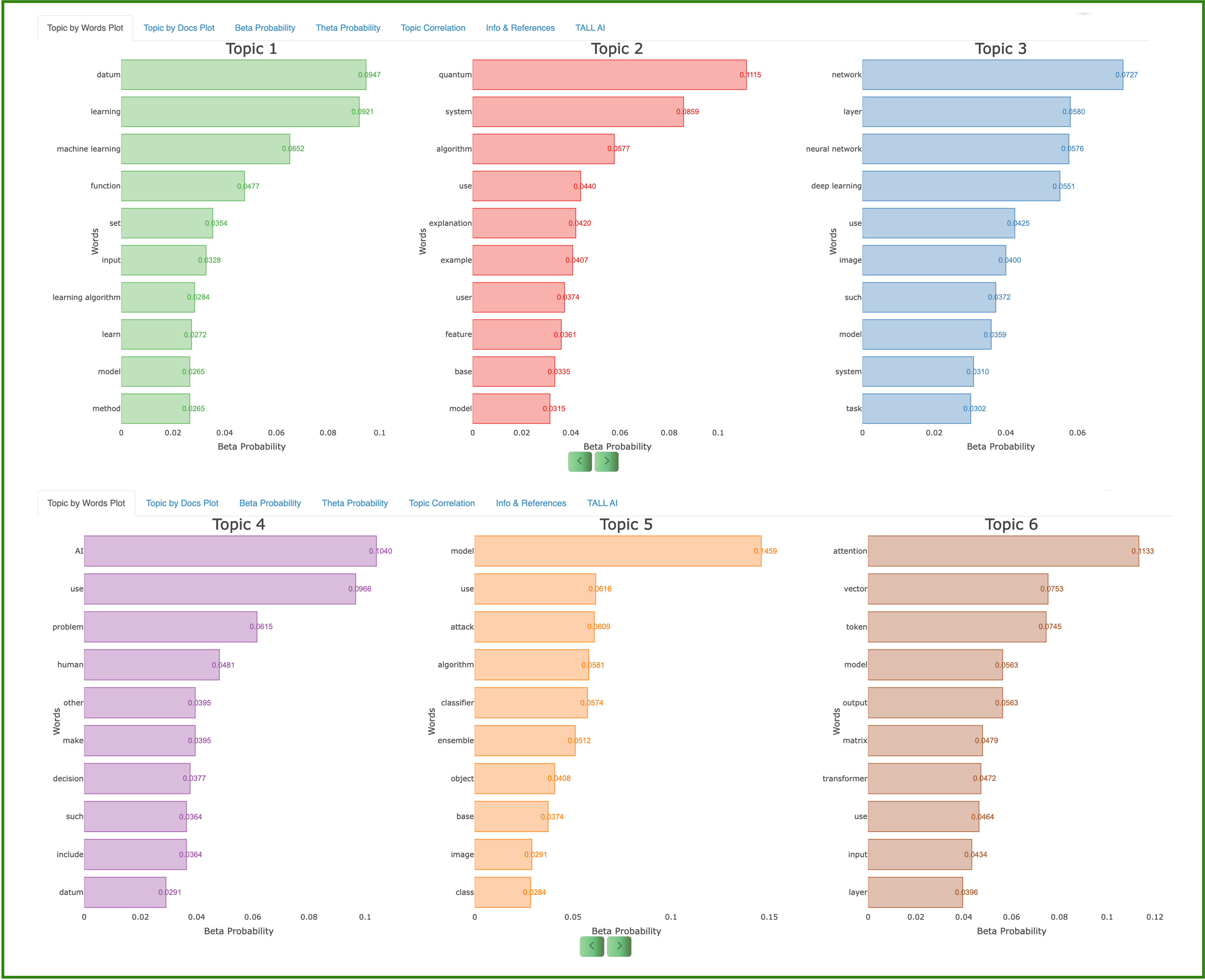
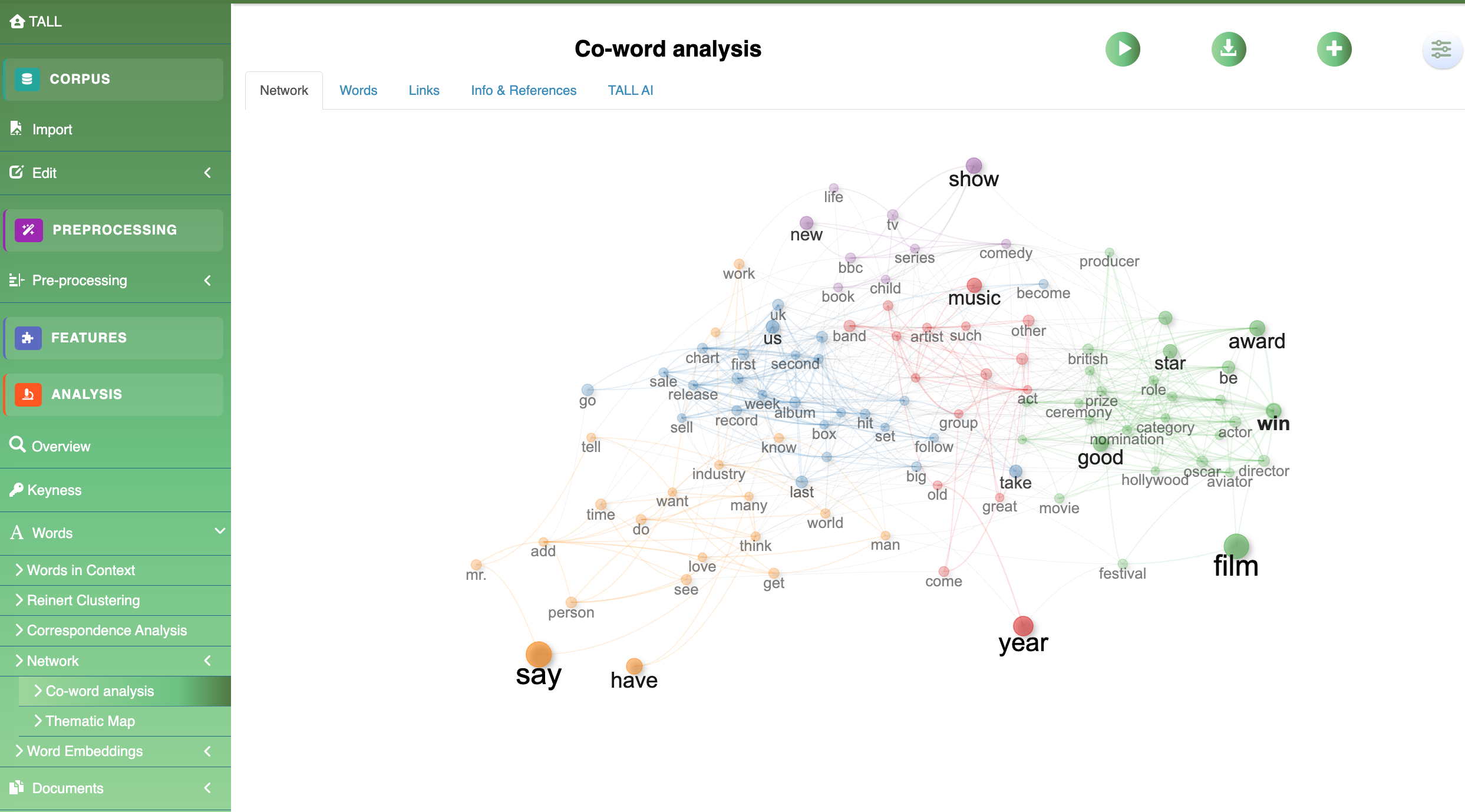
Thematic analysis on BBC News.
A collection of 386 short news articles from the BBC News corpus, retrieved from the BBC website (Greene & Cunningham, 2005). After loading, TALL applies standard pre‑processing — tokenisation and lemmatisation via the EN GUM model — retaining adjectives, nouns, proper nouns, and verbs.
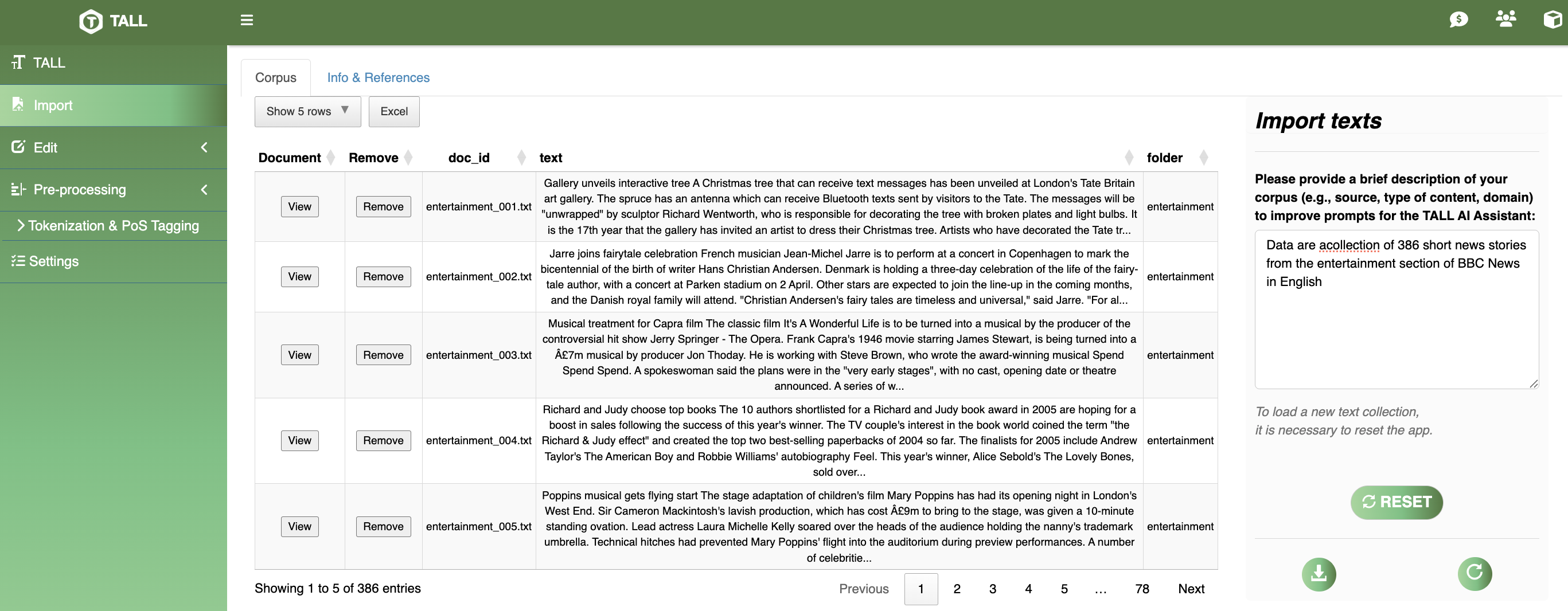
Built‑in BBC News dataset loaded with TALL AI context automatically populated.
EN GUM model selected. Adjectives, nouns, proper nouns, verbs retained.

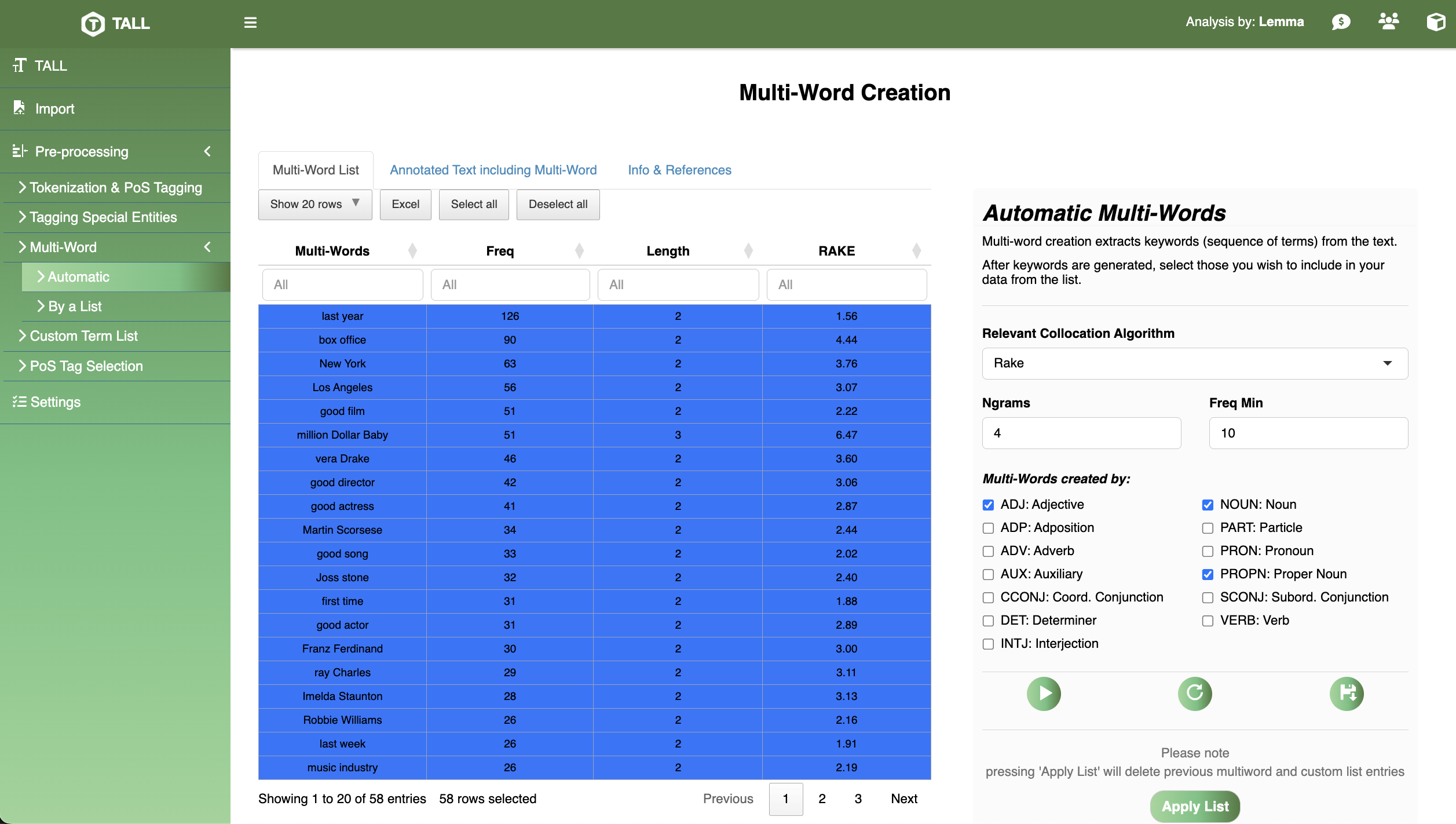
RAKE extracts salient collocations; manual curation preserves domain phrases.
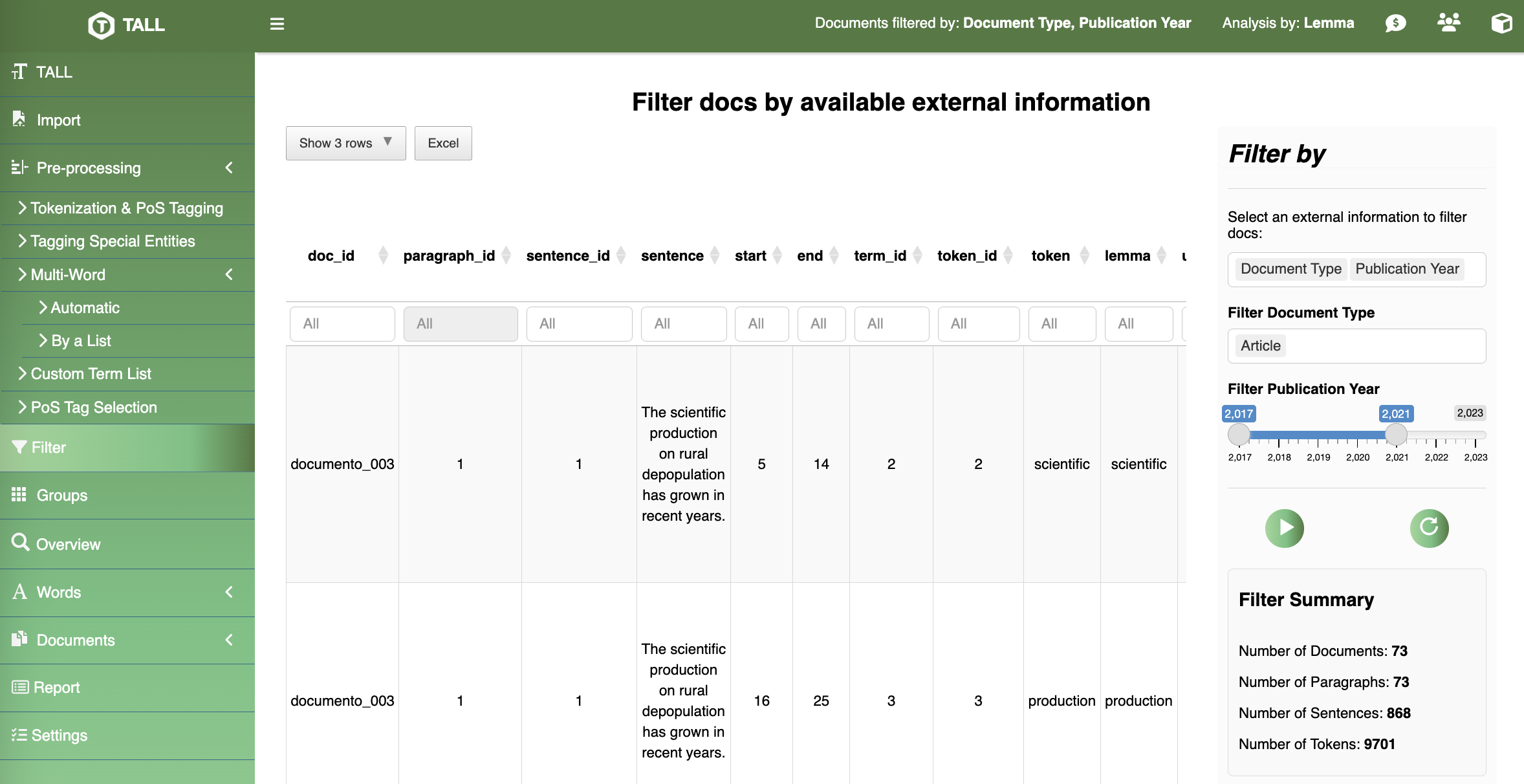
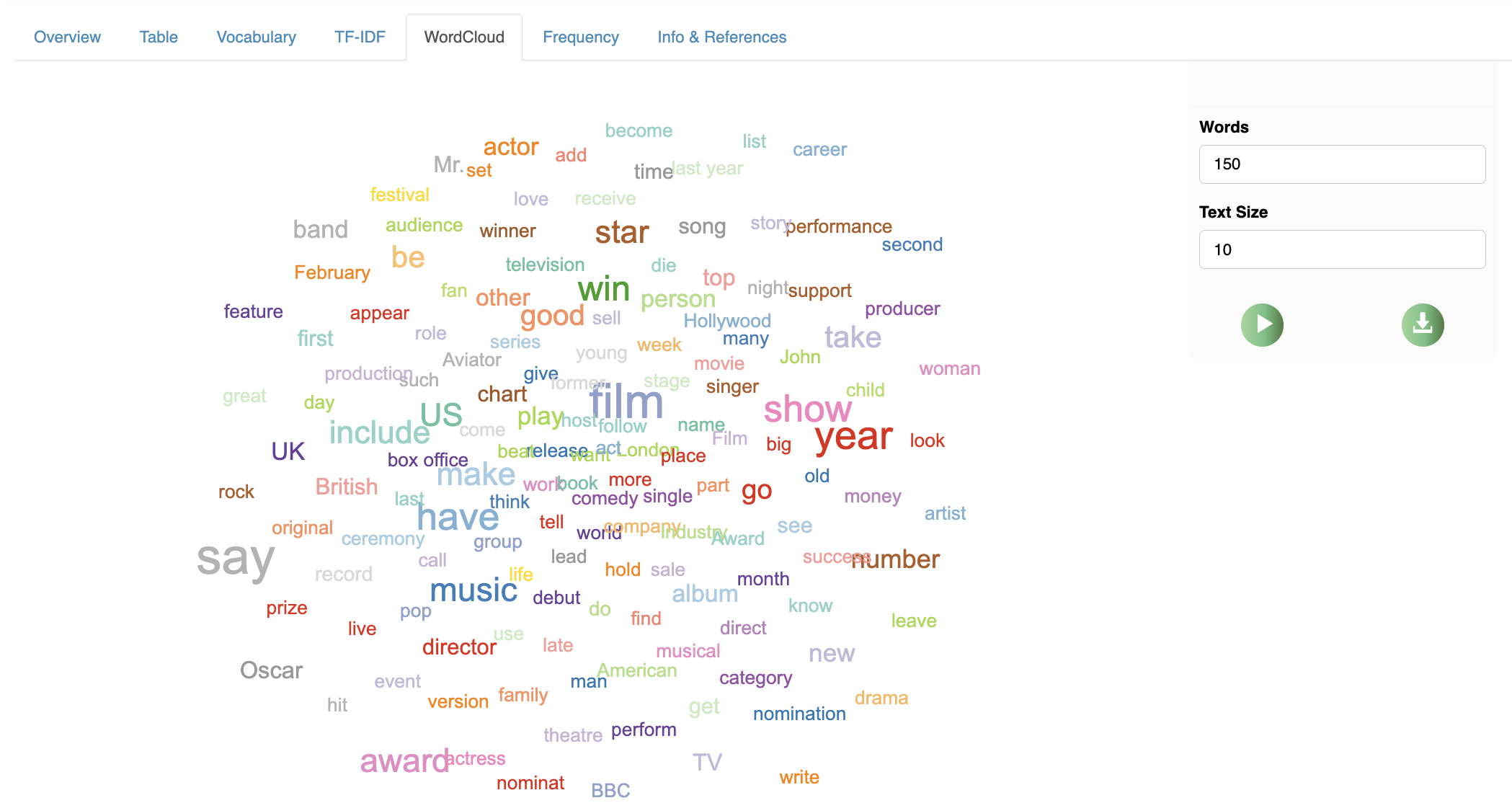
Descriptive statistics, lexical richness, and TF‑IDF for discriminating terms.
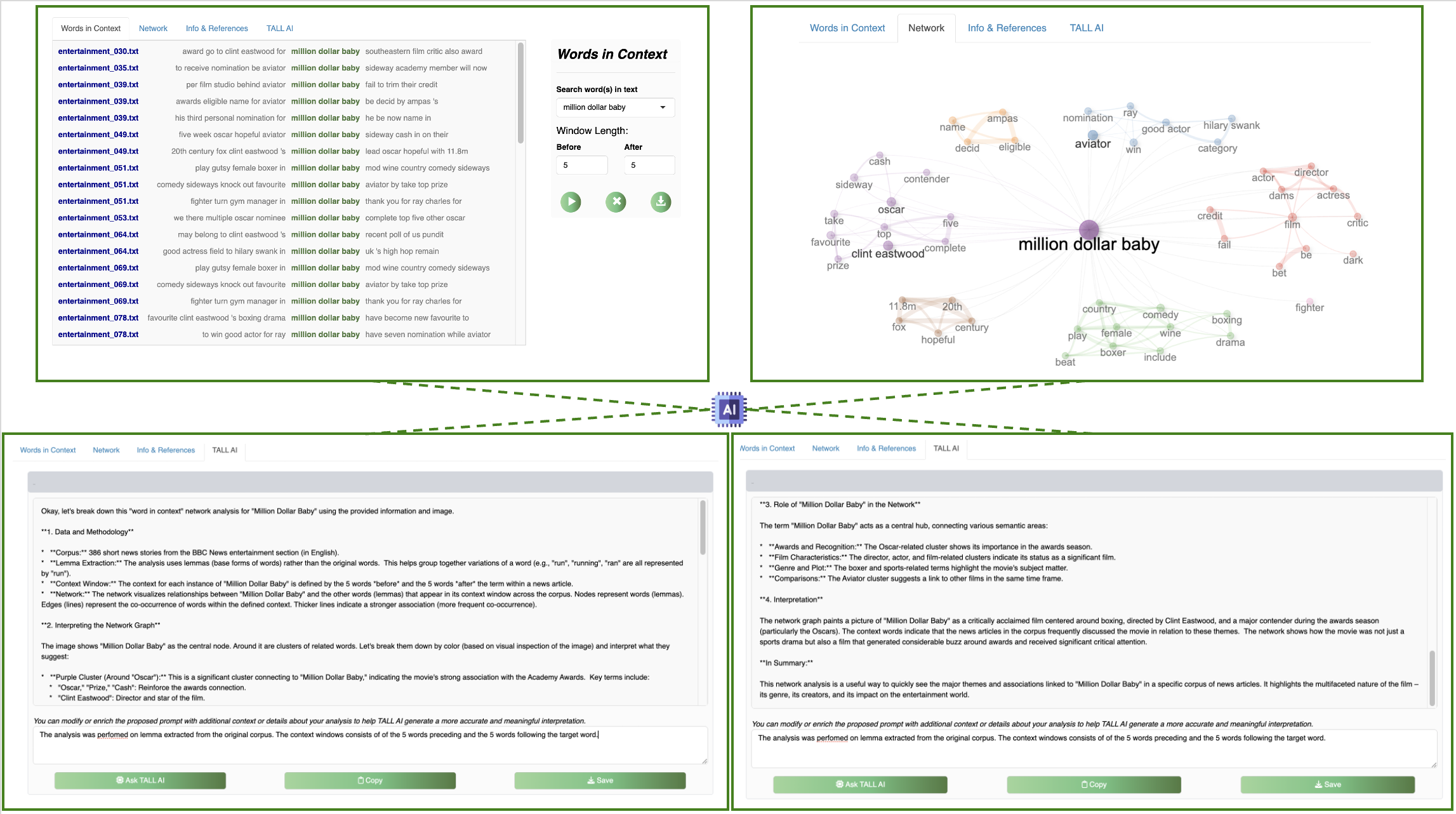
Concordance view surfaces co‑text environments for salient terms.
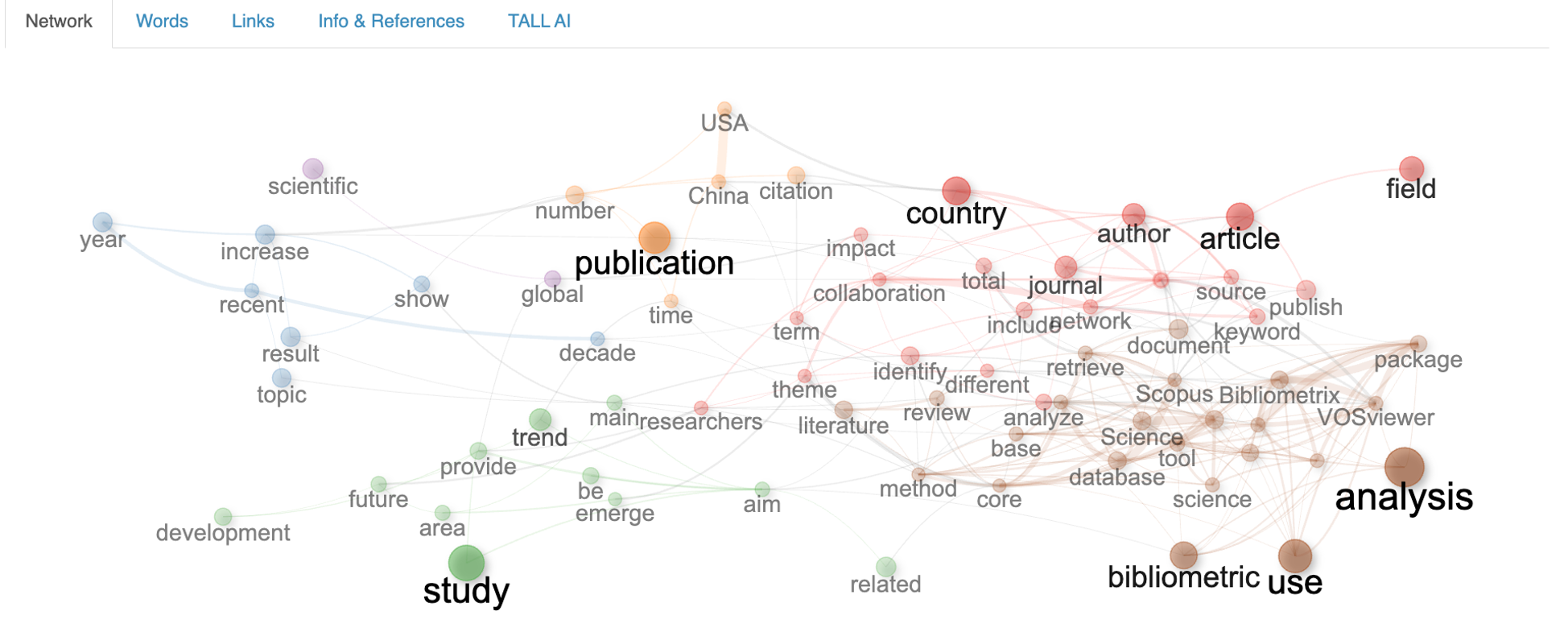
LDA recovers thematic structure across the full news collection.

"The entertainment news focuses heavily on film awards and the movie industry. Music‑related news forms a significant portion of the content — organised around performance, industry and sales."