TALL is organised into three coherent layers — import, pre-processing, and analysis — each composed of modules that run independently or chain into a continuous workflow. Every intermediate result is visible, exportable, and reproducible by design.
Figure The tab‑oriented navigation of TALL guides users through the analytical pipeline in order.
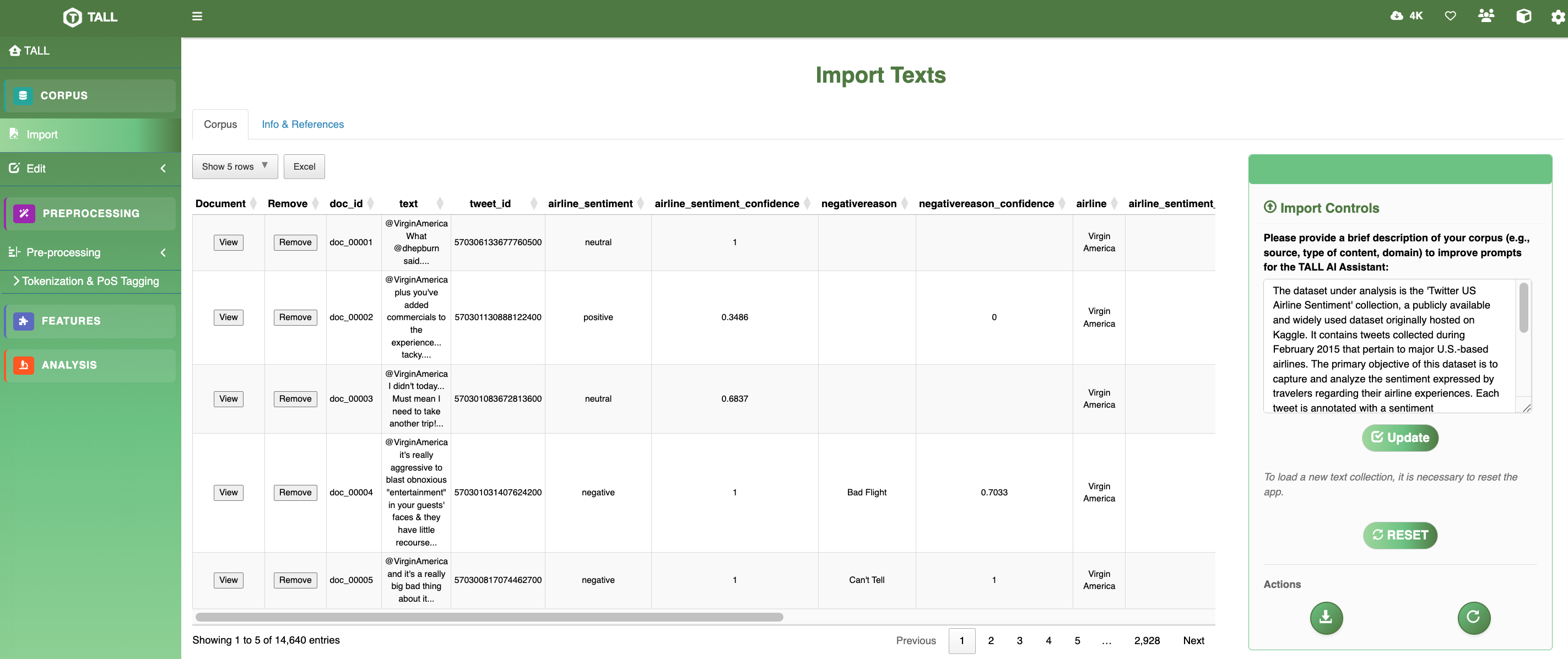
IData import & management
From .txt to .pdf —
a broad, encoding‑aware ingestion.
TALL accepts plain text, CSV, XLSX, and PDF files, with automatic character‑encoding detection to prevent loss of diacritics or non‑ASCII characters. Metadata can be uploaded in parallel — author, date, label — and later used as filters or grouping factors in downstream analyses.
A reactive Data Editor panel provides row filtering, full‑text search, and random or stratified sampling. Large corpora can be segmented into paragraphs, records, or user‑defined units, and edited corpora can be saved for subsequent sessions.
Native integration with the bibliometrix package allows direct ingestion of biblioshiny files for science‑mapping workflows.
· Multi‑format ingestion: TXT, CSV, XLSX, PDF
· Automatic encoding detection
· Interactive data editor with filters & search
· Document segmentation & sampling
· Bibliometrix / biblioshiny compatibility
Figure 2 The import module automatically recognises the dataset and pre‑populates the TALL AI context, enabling context‑aware interpretation from the very first step.
IIPre‑processing
Linguistic annotation
in 56 languages.
TALL ships with 87 pre‑trained models — one per language variant — all derived from Universal Dependencies v2.15 treebanks and accessible through the companion tall.language.models repository.
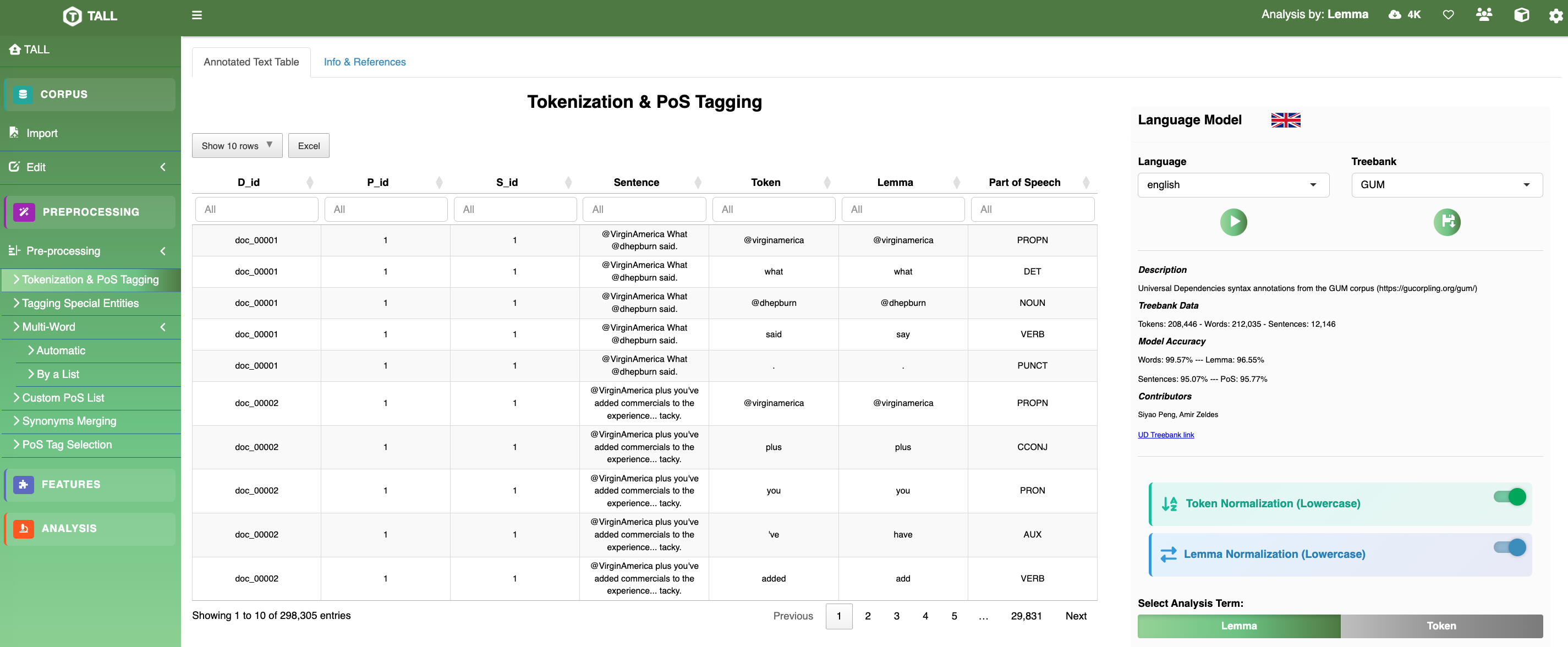
Figure 3 Tokenisation, lemmatisation and PoS tagging. Each row of the annotated dataframe is a token with its lemma and Universal Dependencies PoS tag.
Tokenisation · PoS · Lemmatisation
Powered by the udpipe framework with language‑specific pre‑trained models. Users select tokens or lemmas as the unit of analysis; the choice propagates through all downstream modules.
Custom dictionaries, thesauri, and stopword lists can be uploaded for domain‑specific adaptation of lemmatisation and lexical normalisation.
udpipeUniversal Dependencies v2.1587 language modelsoffline cached
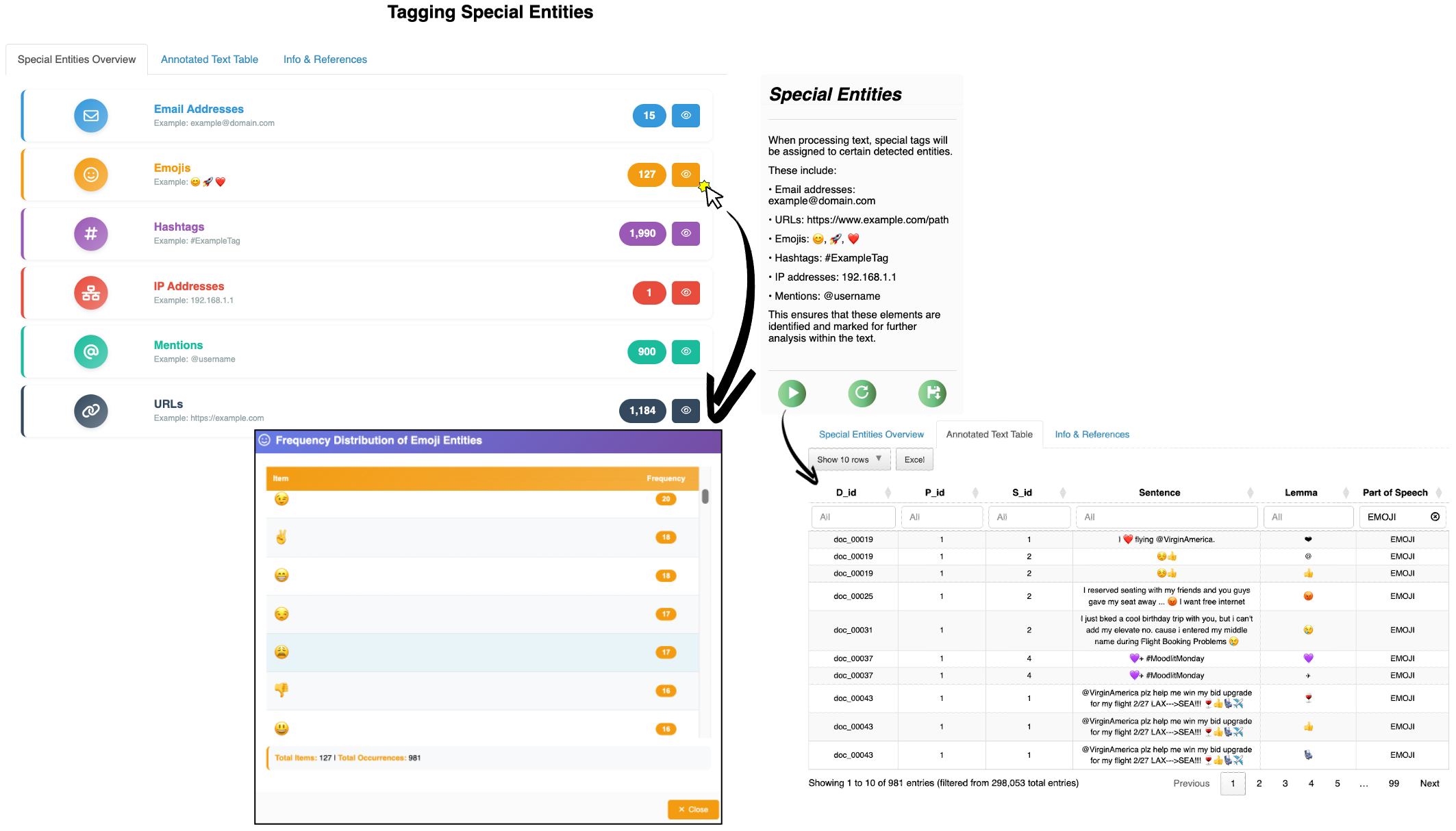
Figure 4 Special entities (emojis, hashtags, mentions) are tagged and can be included as standalone units or combined with standard lexical categories.
Special entities
TALL detects and tags platform‑specific features — emojis, hashtags, user mentions — distinguishing them from standard parts of speech. Their frequency distributions can be visualised and they can flow into downstream analyses as first‑class lexical units.
Paper benchmark on US Airline Tweets corpus: 127 unique emojis, 1,990 unique hashtags, 930 mentions automatically detected.
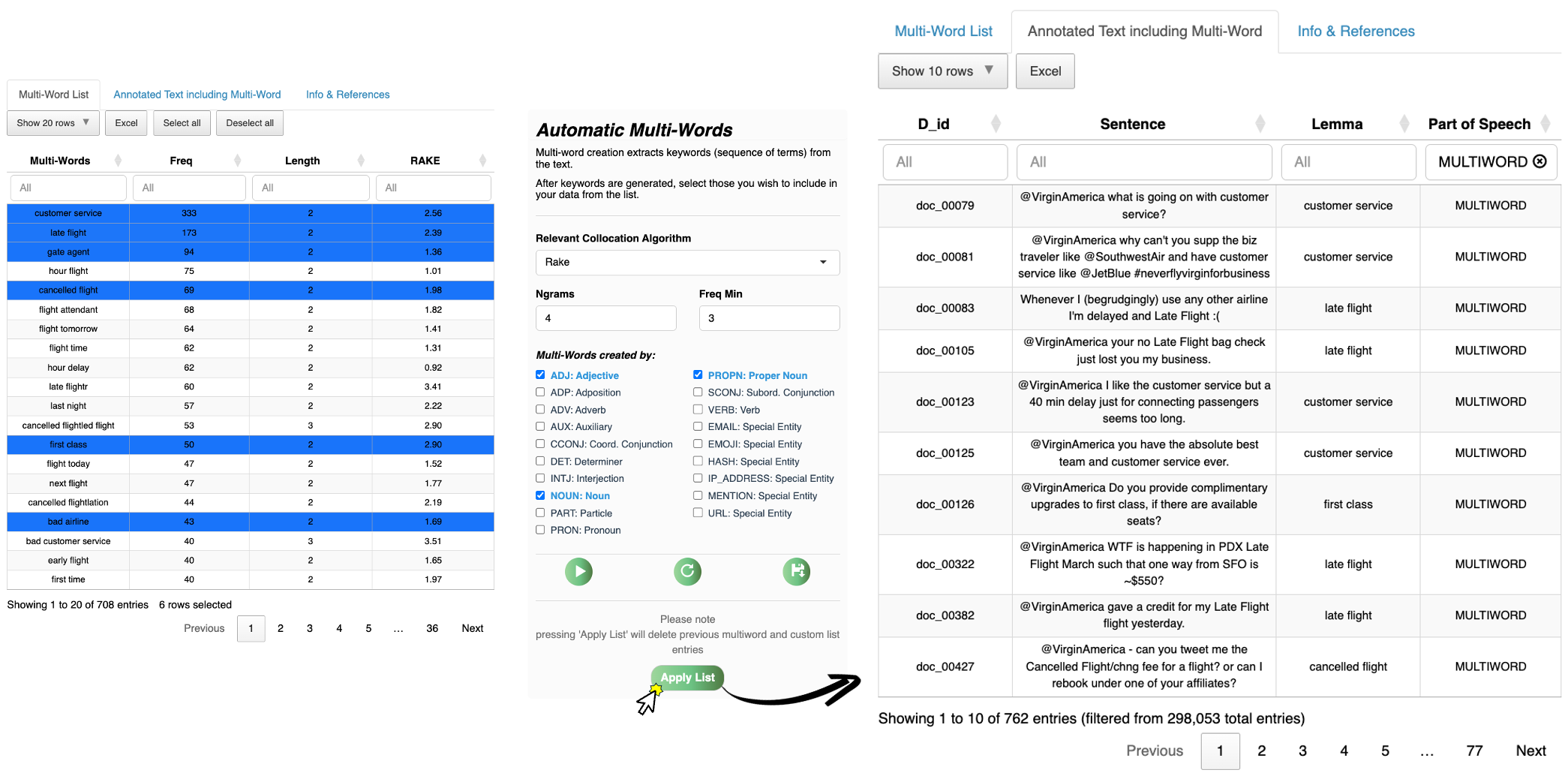
Figure 5 Multi‑word creation and candidate selection. Semantically coherent collocations are surfaced and curated before downstream analysis.
Multi‑word expressions
Four algorithms — including RAKE, Pointwise Mutual Information, and Morrone's IS‑score — identify salient collocations and candidate keyphrases. C++ via Rcpp keeps extraction fast even on large corpora.
Candidates can be curated manually, saved as reusable lists, and tagged in the main dataframe so that multi‑words are treated as single entries in every subsequent analysis.
RAKEPMIIS‑scorecustom lists
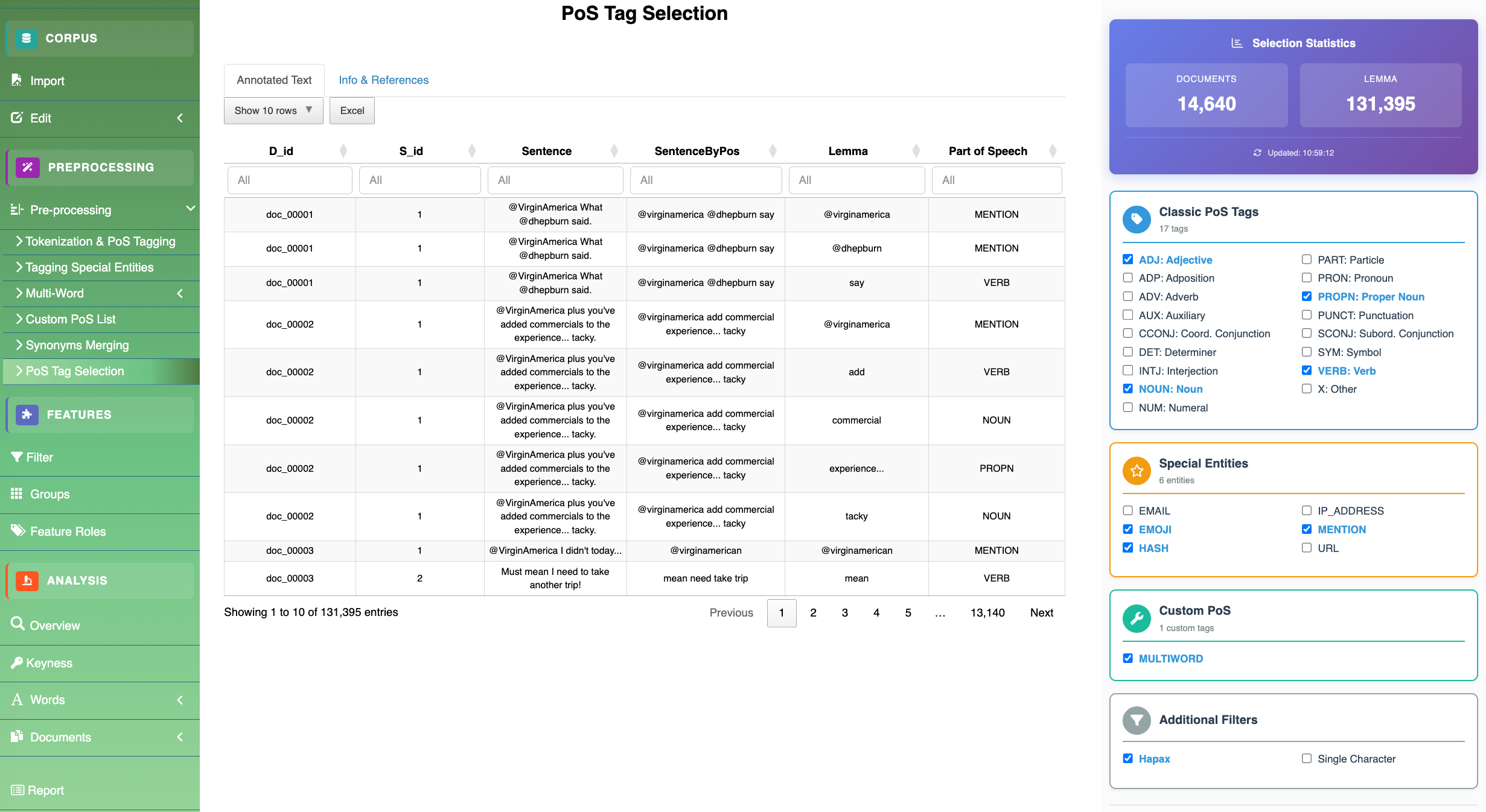
Figure 6 Unified PoS selection mechanism — standard Universal Dependencies tags (NOUN, VERB, ADJ, …) are shown alongside custom categories created in previous steps.
Part‑of‑speech selection
Before moving to word‑ and document‑level analyses, users specify which lexical categories to retain. Standard categories are joined automatically by custom ones generated in earlier steps, so every relevant linguistic unit — conventional or domain‑specific — can be included on equal footing.
IIIAnalysis & visualisation
Fourteen modules. One continuous narrative.
Word‑level and document‑level methods are grouped into coherent families. Each module is independent — you can run just one, or chain them. TALL AI adds a natural‑language interpretation alongside every output.
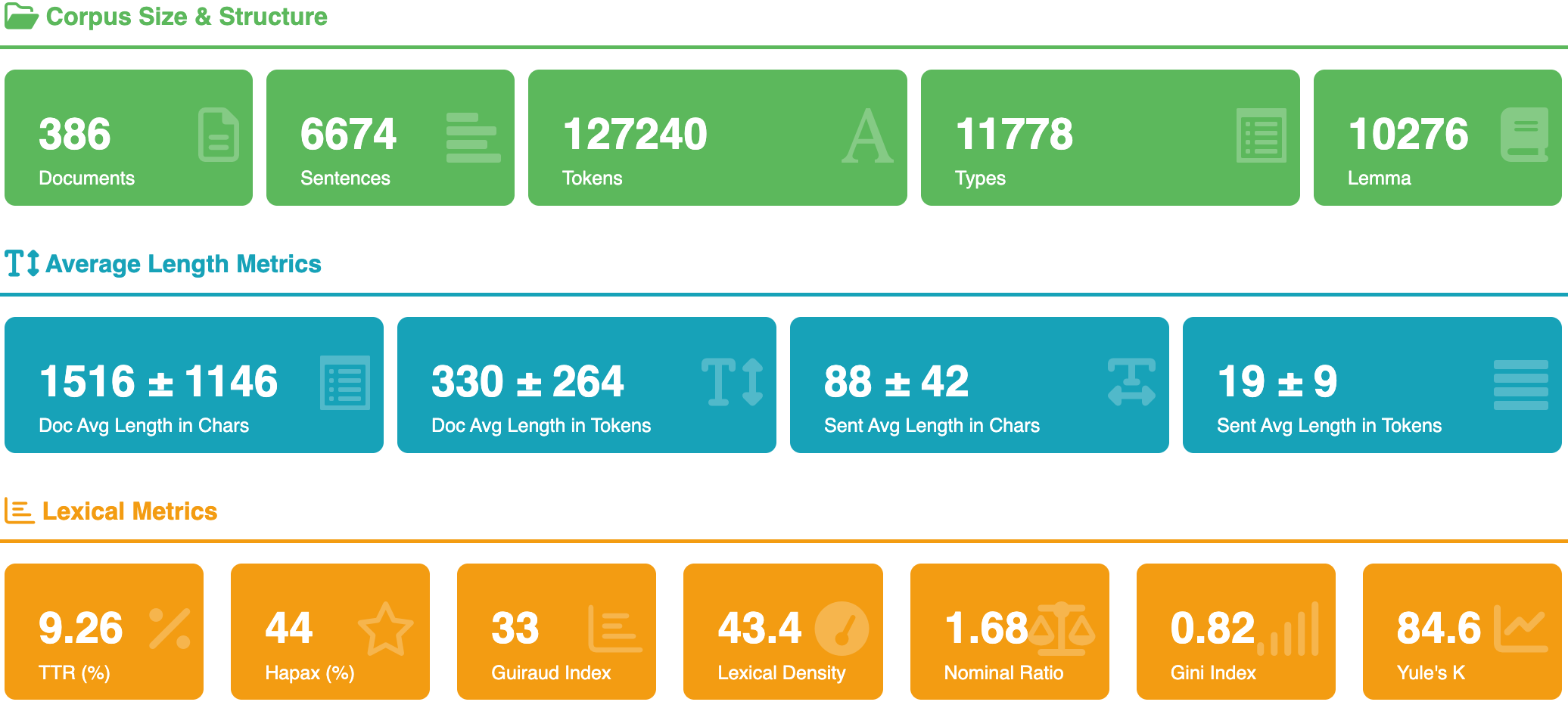
Figure 7 · Overview Descriptive statistics of the BBC News entertainment sub‑corpus — frequency, lexical richness, TF‑IDF, word clouds.
Module · Overview
Descriptive statistics & lexical richness
Frequency distributions, lexical diversity measures, TF‑IDF for discriminating terms across document sets, and interactive word clouds via plotly with zoom and tooltip interactions.
Figure 8 · Words Concordance‑based exploration of @AmericanAirlines mentions across the US Airline Tweets corpus.
Module · Words
Words in Context (KWIC)
Concordance analysis reveals co‑text environments and usage patterns that frequency counts alone cannot surface. Combines classical close reading with AI‑assisted pattern recognition.
Based on Wulff & Baker (2020).
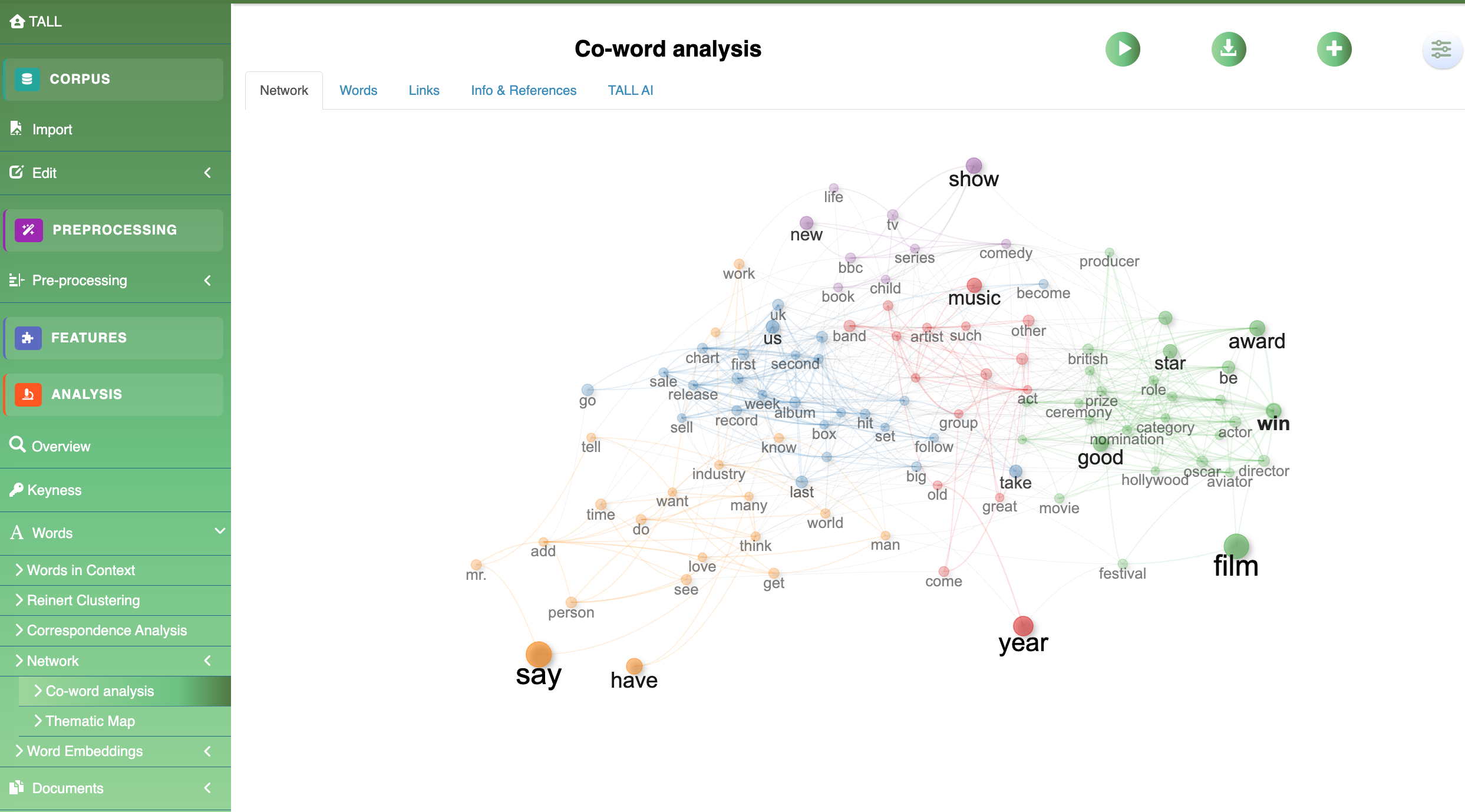
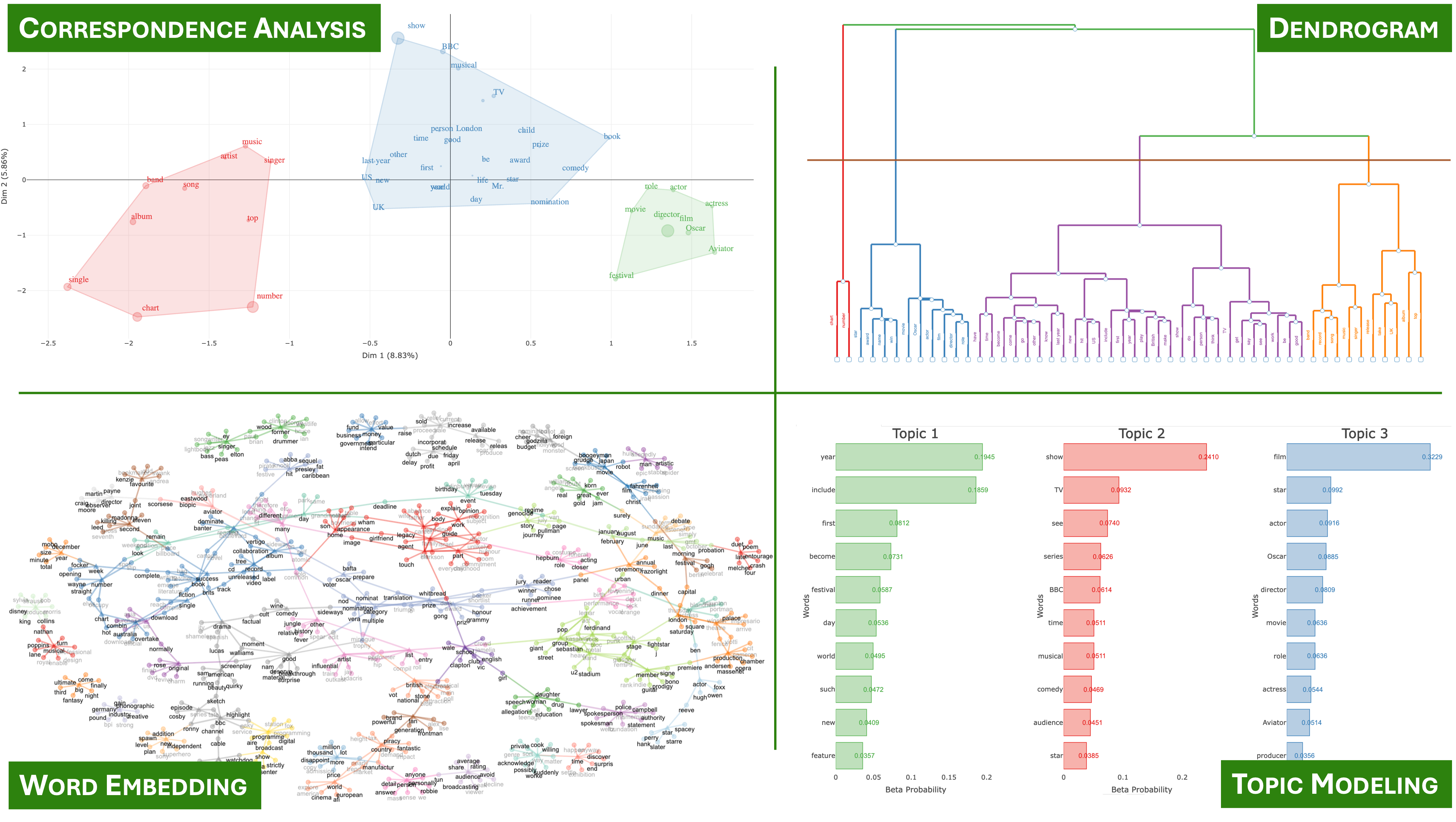
Figure 9 · Network Co‑occurrence network with Louvain community detection. The BBC News example resolves into five dense sub‑graphs — awards, music, industry, media, general.
Module · Words
Co‑occurrence networks & embeddings
Co‑word analysis via igraph and visNetwork with community detection and centrality metrics. Word embeddings through word2vec let you explore semantic relationships interactively.
Version 1.0 adds dependency‑based word networks with filters over syntactic relations — subject, object, modifier, complement — revealing grammatical structures behind the statistical patterns.
Louvaindependency graphsWord2VecReinertCA
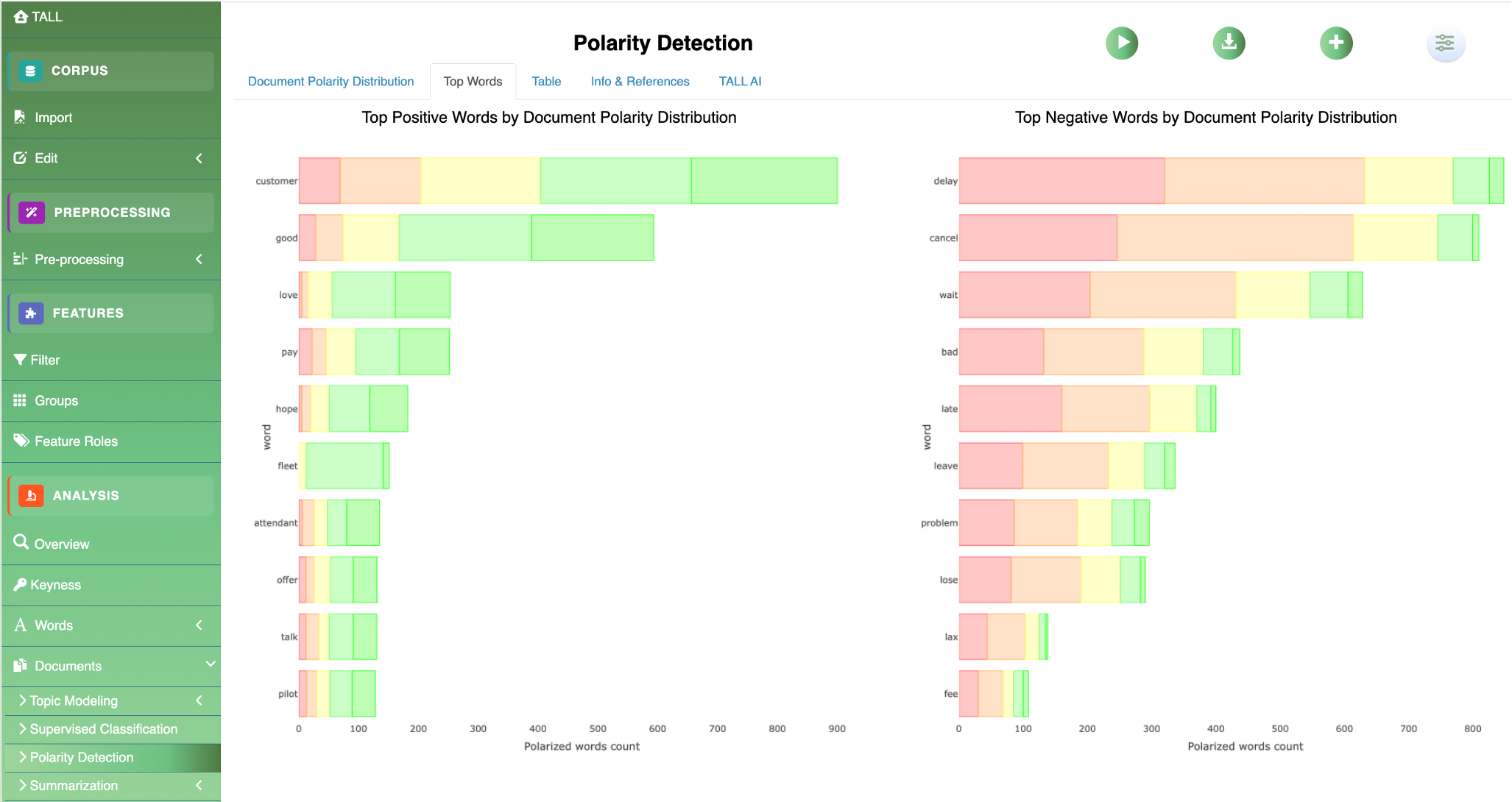
Figure 10 · Documents Top word distributions by polarity category in the US Airline Tweets corpus — negative sentiment clusters around service disruptions and delays.
Module · Documents
Polarity & emotion detection
Three sentiment lexicons side‑by‑side: Hu & Liu, Loughran‑McDonald (finance), and the NRC Emotion Lexicon for eight emotions — anger, anticipation, disgust, fear, joy, sadness, surprise, trust.
Outputs include donut‑chart overall distributions, per‑document breakdowns, and top‑word panels grouped by sentiment category. Context‑sensitive rules handle negation and intensifiers.
Figure 11 · Documents Topic modeling with LDA, CTM and STM. Diagnostics based on coherence and exclusivity support optimal K selection.
Module · Documents
Topic modeling v1.0
Three topic modeling families — Latent Dirichlet Allocation (LDA), Correlated Topic Model (CTM), and Structural Topic Model (STM). Automatic K selection based on coherence and exclusivity diagnostics.
Intensive computations run asynchronously through future and promises, keeping the interface responsive on long runs.
Figure 12 · Documents Extractive summarisation via TextRank plus abstractive options. Key sentences are ranked by centrality and highlighted in context.
Module · Documents
Text summarisation
Extractive summarisation through textrank — similarity graph with centrality ranking for key sentence extraction — plus abstractive summarisation through TALL AI for condensed narrative overviews.
TextRankextractiveabstractive
IVExport & reporting
Ship publication‑ready outputs, not loose screenshots.
All tables and statistics export as CSV or XLSX; visualisations as PNG at configurable DPI for publication quality. The Report module assembles selected outcomes into a single structured XLSX, preserving parameters and preprocessing choices for full provenance.
· CSV / XLSX for tables
· DPI‑aware PNG export
· Cumulative XLSX report
· Save / resume sessions via .tall files
Figure 13 Report customisation — selected outcomes from any module can be assembled into a single structured file for sharing or archiving.
VPerformance
Benchmarked on real hardware.
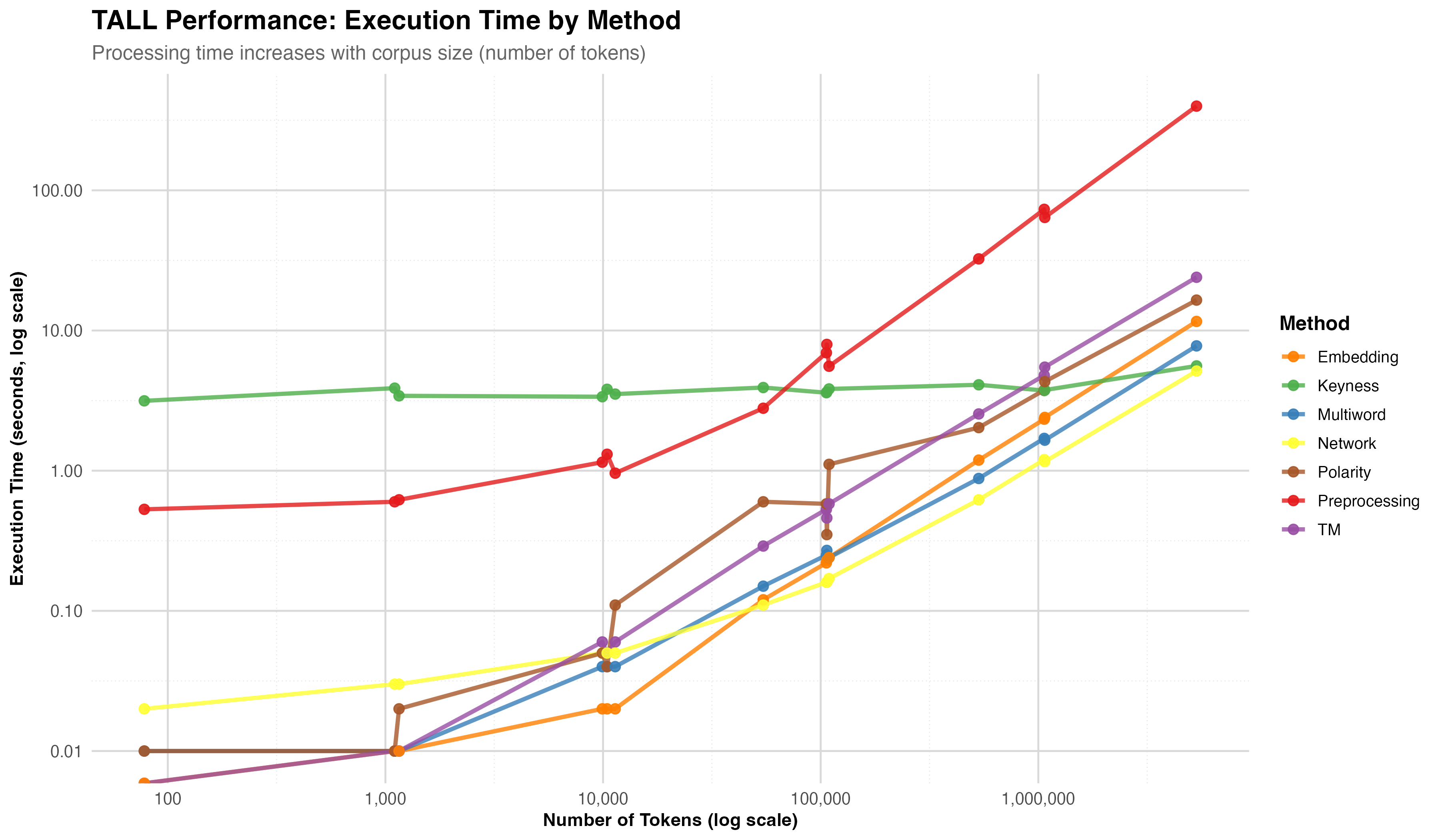
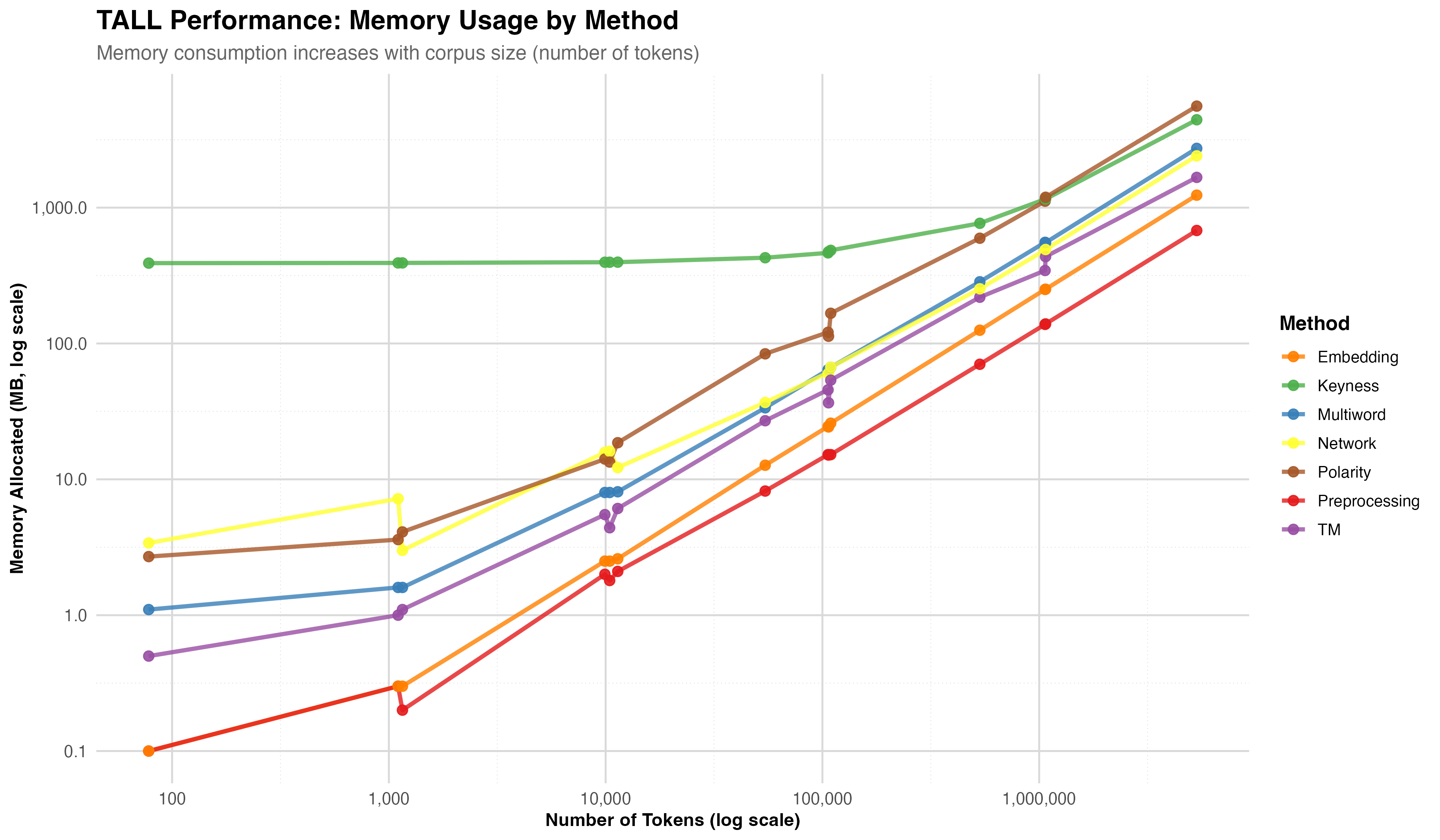
Core operations scale linearly with corpus size. TALL handles tens of thousands of documents on standard research laptops — and supports server deployment for million‑token studies without changing the codebase.
Throughput
14.5k
tokens / second — preprocessing on M4 Pro
Small corpora
1–2GB
RAM for <10⁵ tokens — standard laptops
Scaling ceiling
5.3M
tokens benchmarked — 398s preprocessing
Release channel
CRAN
versioned · FAIR‑compliant · MIT
Figure 14 · Runtime Median execution time for seven core operations across 14 corpus configurations. Log‑log scale.
Figure 15 · Memory Mean peak memory allocation across operations. Keyness analysis is the memory‑bound bottleneck for very large corpora.
Benchmarks on Apple M4 Pro · 48 GB unified memory · R 4.5.2. Full protocol in the paper supplementary material.
VIFAIR by design
Built for the open‑science era.
Every TALL release is versioned on CRAN and tagged on GitHub. Metadata is described through DESCRIPTION, CITATION.cff, and codemeta.json. All dependencies are MIT‑compatible and declared explicitly.
F · Findable
Globally unique identifiers through CRAN & GitHub; tagged releases; rich CRAN metadata; indexed on RDocumentation.
A · Accessible
Open HTTPS retrieval — install.packages("tall"). Historical metadata preserved through CRAN archive & GitHub commit history.