§ 3 · Adoption
Joining a growing community.
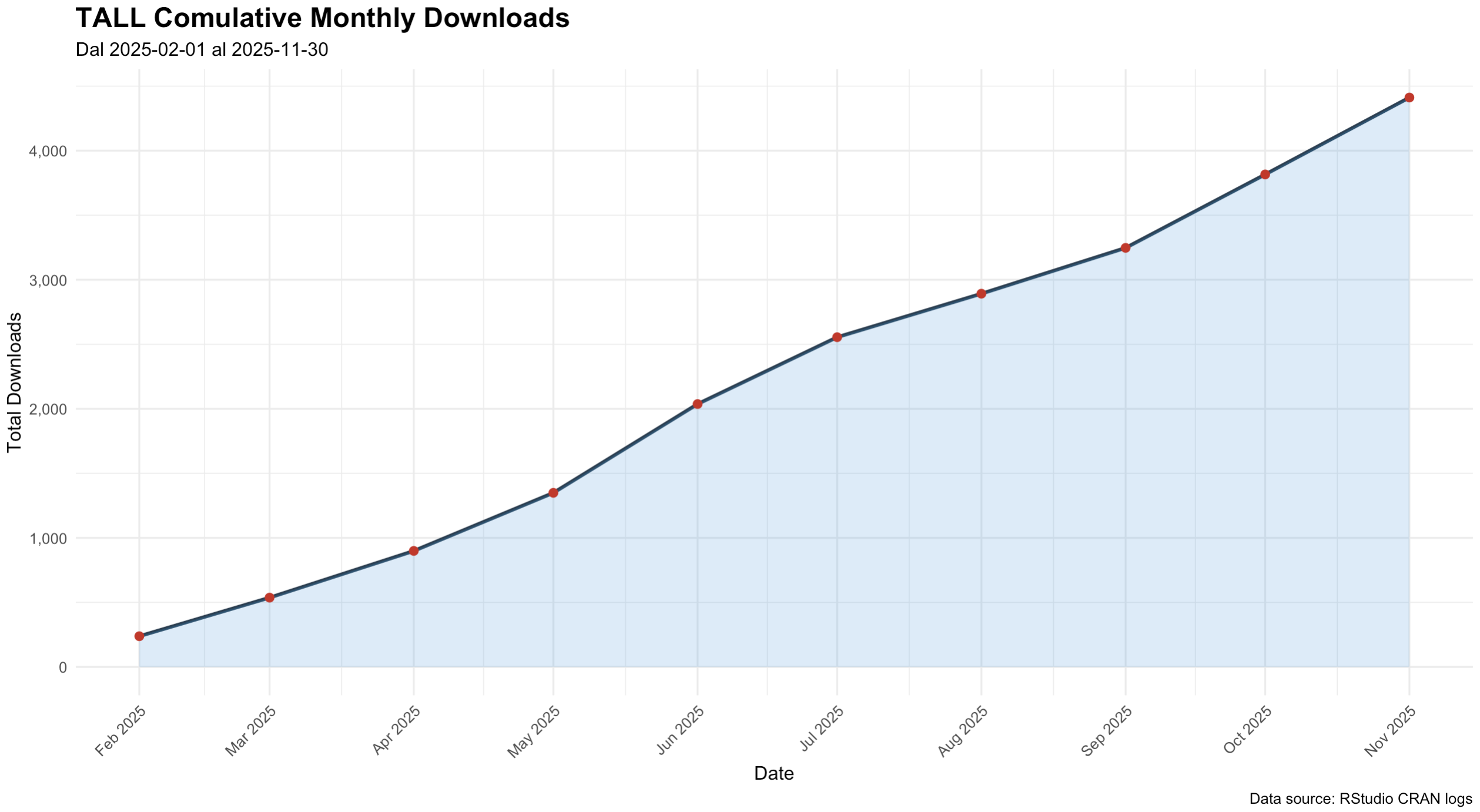
Since its February 2025 CRAN release, TALL has been downloaded more than 4,000 times — sustained monthly growth, with rapid early adoption between April and June 2025. Currently used in postgraduate and doctoral programs at several Italian universities.
4k+
CRAN downloads
Feb 2025
First public release