Six sections of technical detail.
The supplementary appendix complements the paper with complete dependency lists, the FAIR‑principles audit, architecture diagrams, benchmark protocols, adoption analytics, and a step‑by‑step worked example.
Click any section below to expand its contents.
A TALL application dependencies
TALL is built on a curated stack of 42 open‑source R packages covering UI, data I/O, NLP, analytics, network science, async execution, and export. All dependencies are MIT‑ or similarly permissively‑licensed and declared explicitly in the DESCRIPTION file.
Full alphabetical table with repository URLs and descriptions in the supplementary PDF, Table S1.
B FAIR principles for research software
TALL aligns with the FAIR Guiding Principles for research software (Wilkinson et al., 2016). Table S2 of the supplementary material maps each of the 13 criteria to a concrete TALL implementation.
F2 — Rich metadata via
DESCRIPTION, CITATION.cff, codemeta.json.F3 — Metadata links directly to CRAN and GitHub identifiers.
F4 — Indexed on CRAN, GitHub, and RDocumentation.
install.packages("tall").A1.1 — Protocol is open, free, and universal.
A1.2 — Authentication supported where needed (developer access).
A2 — Historical metadata preserved via CRAN archive and GitHub history.
DESCRIPTION, NAMESPACE).I2 —
Authors@R, SPDX license identifiers, CRAN controlled vocabulary.I3 — Dependencies explicitly declared via
Imports; environment requirements in README.
R1.1 — MIT license (SPDX identifier declared).
R1.2 — Full provenance through Git history, release notes, ORCIDs.
R1.3 — Compliant with CRAN and tidyverse community standards.
C Software architecture
TALL adopts a modular, stratified design organised into five sequential layers — each autonomous yet contributing to a coherent end‑to‑end analytical workflow.
-
Data Import & Management
Ingests TXT / CSV / XLSX / PDF through
readtext,pdftools,readxl. Performs automatic encoding detection, metadata integration, and structured integrity checks to prevent downstream failures. -
Text Pre‑processing
Tokenisation, PoS tagging, lemmatisation, and special‑entity recognition via the
udpipeframework, using 87 pre‑trained models spanning 56 languages derived from Universal Dependencies Treebanks. -
Analysis
Three complementary module families: Overview (descriptive stats, TF‑IDF, word clouds), Words (concordances, Reinert clustering, correspondence analysis, networks via
ca/igraph/word2vec), Documents (topic modelling, polarity, summarisation viatopicmodels/textrank). -
TALL AI Assistant
Interpretive layer built on the Google Gemini API. Generates context‑aware natural‑language explanations alongside statistical outputs, enabling hybrid quantitative + qualitative analysis.
-
Output & Visualisation
Interactive dashboards via
plotlyandvisNetwork, reproducible XLSX reports viaopenxlsx. Captures imported data, preprocessing steps, parameters, and outputs in a structured archival format.

D Computational performance benchmarks
Comprehensive benchmarking of seven core operations across 14 corpus configurations spanning four orders of magnitude. All tests conducted on a standardised research workstation with corpora sampled with replacement from Herman Melville's Moby Dick.
Apple M4 Pro · 14 cores (10P + 4E) · ARM
48 GB unified memory · macOS 15.3
R 4.5.2 · TALL 0.5.1
10 iterations per config · median time
mean peak memory · bench package
14 corpus configurations · 7 operations
| Operation | Scaling | 5.3M tokens · time | Peak memory |
|---|---|---|---|
| Preprocessing (tokenize · lemmatize · PoS) | O(n) | 398.78 s | 678 MB |
| Multiword (RAKE, Rcpp) | sub‑linear | 7.77 s | 2.7 GB |
| Keyness (reference χ²) | vocab‑bound | 5.59 s | 4.4 GB |
| Topic modelling (LDA, k=5) | parallelised | 23.98 s | 1.7 GB |
| Word embeddings (Word2Vec) | parallelised | 11.61 s | 1.2 GB |
| Network (Louvain) | linear | 5.14 s | 2.4 GB |
| Polarity (Hu‑Liu) | linear | 16.48 s | 5.6 GB |
Key findings. Preprocessing processes ~14,500 tokens/sec with stable linear scaling. Rcpp‑optimised modules (multi‑word, Reinert) remain fast at all scales. Keyness analysis is the memory bottleneck on large corpora, driven by reference vocabulary size rather than token count.
Small corpora (<10⁵ tokens) fit comfortably in 1–2 GB RAM. Medium corpora require ~5 GB. Large corpora (>10⁶ tokens) benefit from institutional server deployment.
E Adoption & CRAN downloads
Since its initial CRAN release in February 2025, TALL has exceeded 4,000 cumulative downloads by November 2025 (source: CRANlogs). Download curve shows marked acceleration between April and June 2025 during the early‑adoption phase, followed by sustained near‑linear growth through the rest of the year.
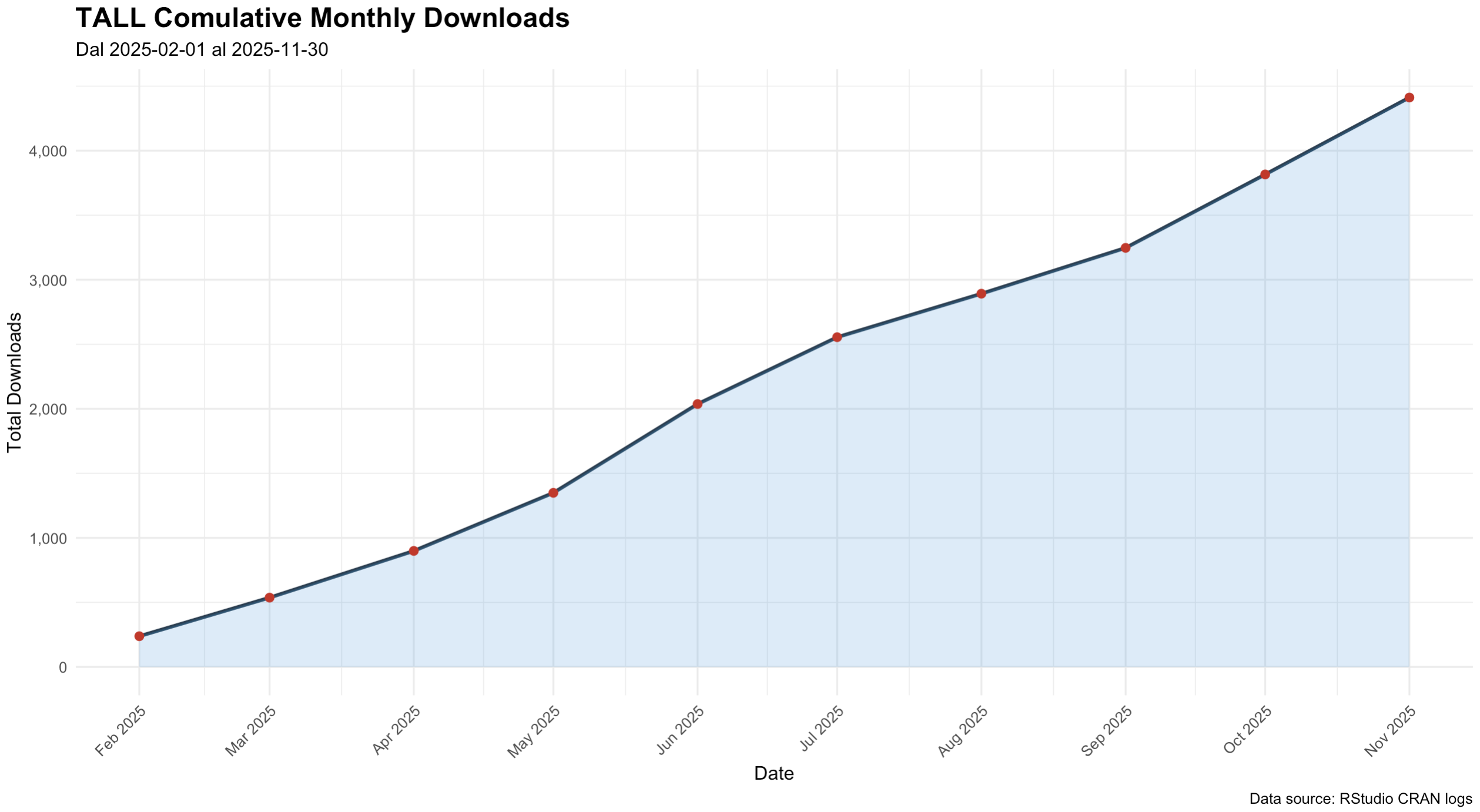
tall package from CRAN, February — November 2025.The trajectory confirms both early visibility and continued integration into analytical workflows within the R research ecosystem. TALL is currently used in postgraduate and doctoral programs at several Italian universities.
F Step‑by‑step worked example
A practical demonstration on the built‑in US Airline Tweets corpus — 14,640 tweets directed at six major US airlines in February 2015. Illustrates social‑media analytics, sentiment detection, and customer‑feedback analysis without requiring programming expertise.
-
1Import & AI context
Built‑in dataset loaded; TALL AI automatically receives a pre‑configured context so every subsequent interpretation is dataset‑aware.
-
2Tokenisation & PoS tagging
English selected as source language; pre‑trained EN GUM model employed. Unit of analysis set to lemma.
-
3Special‑entity recognition
Automatic tagging of 127 unique emojis, 1,990 unique hashtags, and 930 user mentions as first‑class lexical units.
-
4Multi‑word detection
RAKE algorithm surfaces collocations like "customer service", "late flight", "flight attendant". Frequency‑ranked and manually curated.
-
5PoS selection
Retained categories:
NOUN,PROPN,ADJ,HASH,MULTIWORD— unified mechanism lets standard and custom categories coexist. -
6Overview + Words in Context
Descriptive statistics; TALL AI recommends Word‑in‑Context and Polarity Detection as next steps. Concordances for
@AmericanAirlinesreveal customer‑service discourse. -
7Polarity detection
Hu‑Liu lexicon · 48.6% neutral, 28.0% negative (dominated by delay, cancel, miss), 23.4% positive (thank, good, great, appreciate).
"The dominance of delay and cancel in negative tweets suggests airlines should focus on improving their processes for handling flight disruptions."
